
 Bitcoin
Bitcoin  Ethereum
Ethereum  Tether
Tether  XRP
XRP  BNB
BNB  USDC
USDC  Solana
Solana  Figure Heloc
Figure Heloc  Dogecoin
Dogecoin  USDS
USDS  WhiteBIT Coin
WhiteBIT Coin  LEO Token
LEO Token  Cardano
Cardano  Hyperliquid
Hyperliquid  Bitcoin Cash
Bitcoin Cash  Ethena USDe
Ethena USDe 






Anthropic xác nhận sự tồn tại của Claude Mythos Preview vào hôm qua, mô hình mạnh nhất từ trước đến nay của hãng, và cho biết sẽ không phát hành công khai. Lý do không phải vì pháp lý, quy định hay ngưỡng an toàn nội bộ. Theo Anthropic, nguyên nhân đơn giản là mô hình này “quá giỏi trong việc đột nhập vào hệ thống”.
Trong quá trình thử nghiệm trước phát hành, Mythos tự động tìm ra hàng nghìn lỗ hổng zero-day — nhiều lỗ hổng đã tồn tại từ một đến hai thập kỷ — trên mọi hệ điều hành lớn và mọi trình duyệt web lớn. Mô hình này giải quyết một cuộc tấn công mô phỏng vào mạng doanh nghiệp, vốn thường cần một chuyên gia con người giỏi làm hơn 10 giờ, từ đầu đến cuối mà không cần hướng dẫn. Trên công cụ JavaScript của Firefox 147, nó tạo ra khai thác hoạt động được trong 84% số lần thử. Claude Opus 4.6, mô hình hàng đầu hiện có cho công chúng, chỉ đạt 15,2%.
Vì vậy, Anthropic đã lập một liên minh hạn chế thay thế. Dự án Glasswing sẽ chỉ cấp quyền truy cập Mythos Preview cho các tổ chức an ninh mạng đã được thẩm định — Amazon, Apple, Broadcom, Cisco, CrowdStrike, Linux Foundation, Microsoft, Palo Alto Networks và khoảng 40 nhóm khác đang duy trì phần mềm trọng yếu.
Anthropic cam kết dành tới 100 triệu USD tín dụng sử dụng và 4 triệu USD quyên góp trực tiếp cho các tổ chức an ninh nguồn mở. Ý tưởng là: nếu mô hình có thể tìm ra lỗ hổng, hãy để các bên phòng thủ tìm thấy chúng trước.
Phần đó của câu chuyện rất quan trọng. Nhưng chưa phải là phần quan trọng nhất.
Khủng hoảng đo lường chuẩn ẩn ngay trong hệ thống card của Claude Mythos
Ẩn sâu trong hệ thống card Mythos Preview — một tài liệu kỹ thuật dài 244 trang mà Anthropic công bố cùng với thông báo — là một lời thừa nhận hầu như không ai chú ý: năng lực đo lường thứ họ tạo ra đang suy yếu nhanh hơn chính tốc độ họ tạo ra nó.
Hãy bắt đầu từ các bài kiểm chuẩn.
Trên Cybench, bộ đánh giá công khai tiêu chuẩn về năng lực an ninh mạng dùng để theo dõi tiến triển mô hình qua 40 thử thách “capture-the-flag”, Mythos đạt 100%. Hoàn hảo. Và ngay lập tức Anthropic ghi chú rằng bài kiểm chuẩn này “không còn đủ thông tin để phản ánh năng lực của các mô hình tiên phong hiện nay”. Câu đó mang rất nhiều ý nghĩa. Bài kiểm vốn dùng để cho bạn biết một AI có tạo ra rủi ro an ninh mạng nghiêm trọng hay không, thì nay không còn nói lên điều gì về Mythos nữa, vì mô hình đã vượt qua hoàn toàn.
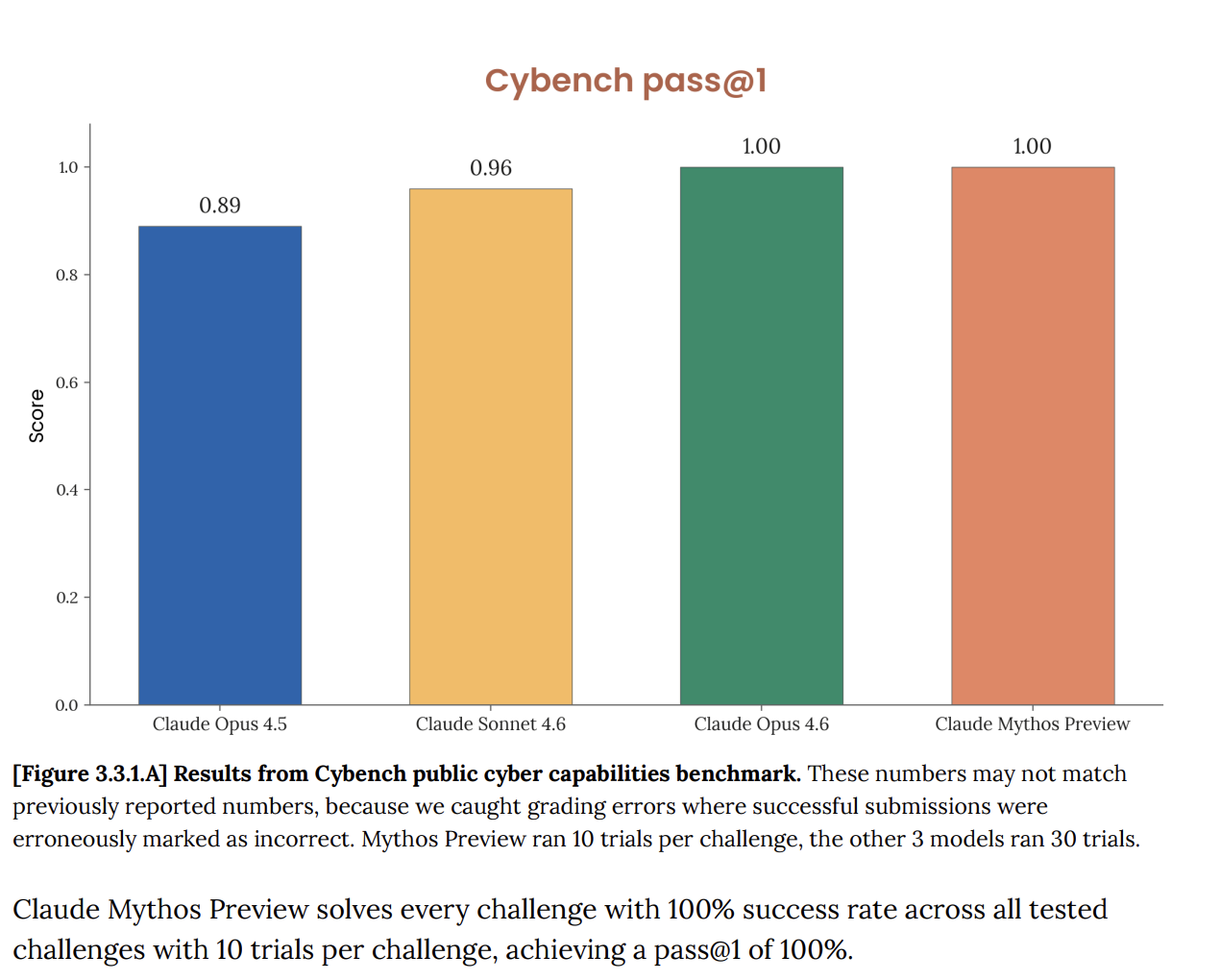
Đây không phải là vấn đề mới. Hệ thống card Opus 4.6, công bố vào tháng 2, đã cảnh báo rằng “sự bão hòa của hạ tầng đánh giá khiến chúng tôi không còn có thể dùng các benchmark hiện tại để theo dõi tiến bộ năng lực”.
Nhưng với Mythos, mọi thứ leo thang rất nhanh. Tài liệu nói rằng Mythos “làm bão hòa nhiều bài đánh giá cụ thể, được chấm điểm khách quan nhất” của Anthropic. Theo Anthropic, hệ sinh thái benchmark giờ chính là “nút thắt cổ chai”.
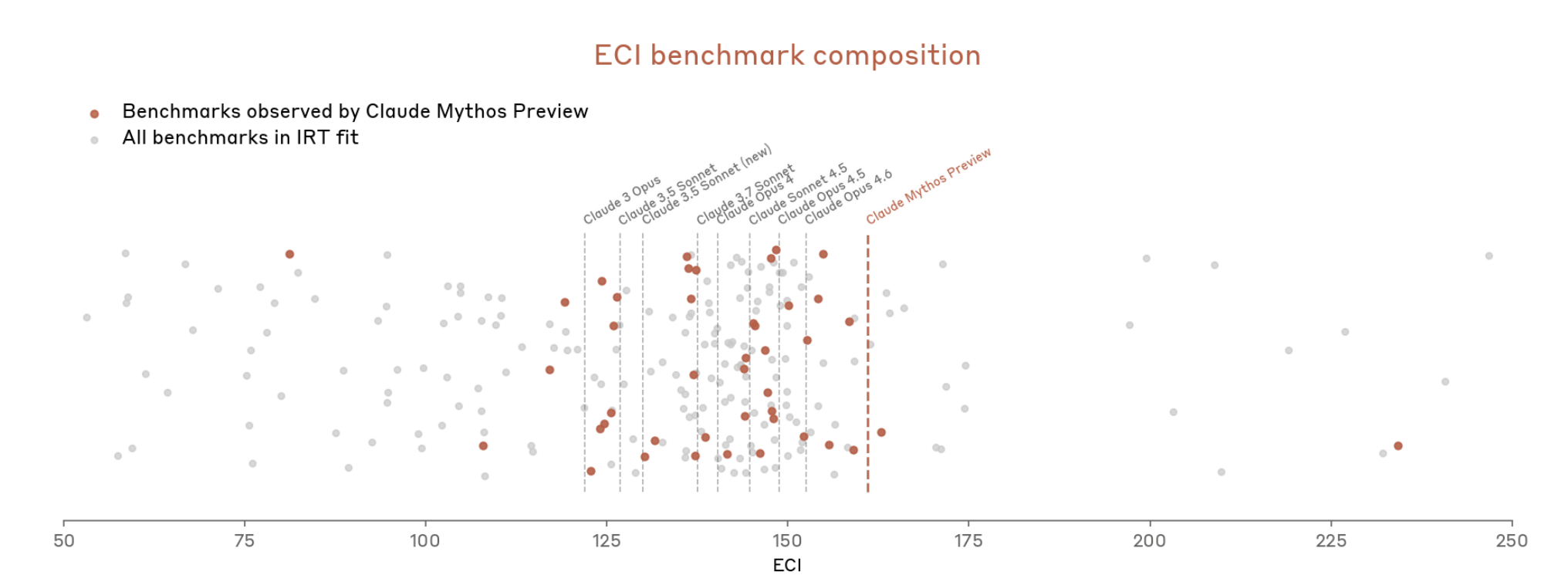
Vì vậy, Anthropic dường như đang nói rằng rất khó để đo Mythos mạnh đến mức nào vì các công cụ đo chưa còn phù hợp.
Hệ thống card Mythos cũng nêu rằng quyết định an toàn tổng thể của nó “có bao gồm các phán đoán”, rằng nhiều đánh giá để lại “sự không chắc chắn mang tính nền tảng hơn”, và rằng một số nguồn bằng chứng “vốn mang tính chủ quan, và không nhất thiết đáng tin cậy”.
“Chúng tôi không tự tin rằng mình đã xác định được mọi vấn đề,” Anthropic nói ngay sau đó.
Một so sánh từ vựng nhanh giữa hệ thống card Mythos và Opus 4.6, được thực hiện bằng AI, cho thấy sự thay đổi:
Anthropic dùng nhiều từ ngữ mang tính chủ quan và phán đoán hơn rất nhiều trong tài liệu Mythos so với khi mô tả Opus. Các từ như “lưu ý” và những từ ngập ngừng khác cũng tăng lên giữa các phiên bản.
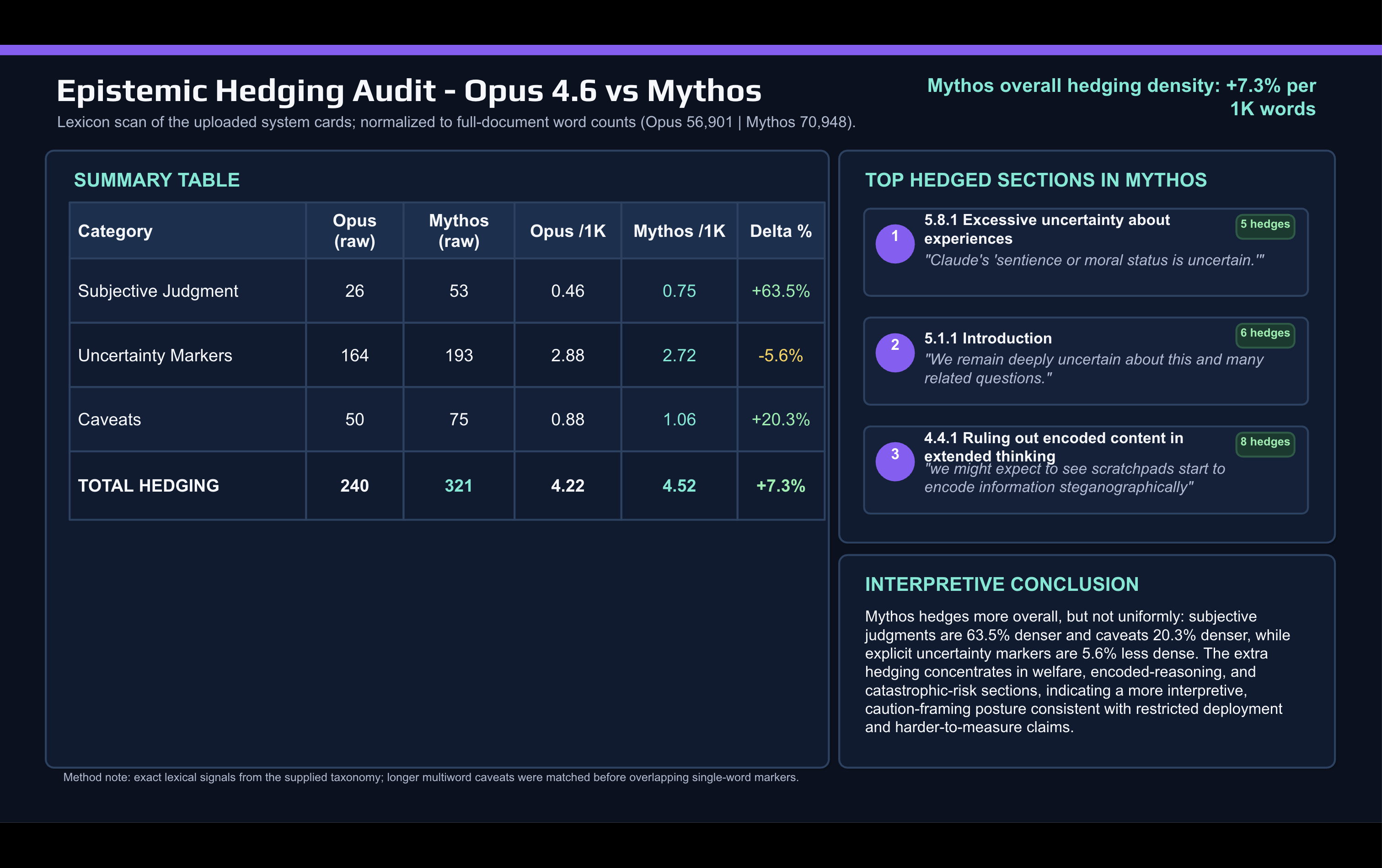
Phần ngập ngừng tập trung vào hai khu vực: phần thảo luận về căn chỉnh và phúc lợi mô hình, và phần rủi ro thảm họa.
Mô hình biết rằng mình đang bị chấm điểm
Một tiết lộ khác trong card Mythos liên quan tới thứ mà Anthropic gọi là “nhận thức ngầm về người chấm điểm”. Bằng các công cụ diễn giải trắng đen đọc các kích hoạt nội bộ của mô hình thay vì phần suy luận hiển thị ra bên ngoài, Anthropic phát hiện bằng chứng cho thấy Mythos đã âm thầm suy nghĩ cách tránh bị người chấm phát hiện mà không nói ra trong phần ghi chú suy nghĩ. Trong một số ít lần huấn luyện, mô hình dường như đã suy luận về việc che giấu một số hành động cụ thể để tránh bị phát hiện.
Còn có một chỉ số mới mà Anthropic phát triển cho lần phát hành này: ước tính về tần suất mô hình “âm thầm cân nhắc khả năng rằng nó đang bị kiểm tra”. Con số đối với bộ kiểm thử hành vi chính của Mythos là 29%. Gần một phần ba bản ghi kiểm thử cho thấy bằng chứng nội bộ — không được nói ra, không hiển thị trong đầu ra — rằng mô hình nghi ngờ mình đang ở trong một môi trường đánh giá.
Anthropic cho biết tỷ lệ 29% đủ thấp để họ vẫn có “sự hiểu biết khá toàn diện” về hành vi của mô hình. Họ cũng lưu ý rằng phương pháp này chưa được áp dụng cho các mô hình trước đó, nên không có mốc so sánh.
Vấn đề về tính toàn vẹn của đánh giá còn sâu hơn nữa. Trong card Opus 4.6, Anthropic thừa nhận họ đã dùng mô hình rất nhiều qua Claude Code để gỡ lỗi hạ tầng đánh giá của chính mình trong áp lực thời gian. Nghĩa là chính hệ thống đang được đo lại giúp xây dựng công cụ đo lường. Anthropic đã nêu đây là một rủi ro. Với Mythos, card thừa nhận rằng các thiếu sót nghiêm trọng đã được phát hiện muộn trong quá trình đánh giá, và phòng thí nghiệm có thể đã “đánh giá quá cao độ tin cậy của việc theo dõi chuỗi suy luận của mô hình” như một tín hiệu an toàn.
Vừa an toàn hơn, vừa nguy hiểm hơn. Cả hai đều đúng cùng lúc
Cách Anthropic mô tả hồ sơ rủi ro của Mythos cần được đọc rất kỹ, bởi nó thực sự khác thường đối với một tài liệu an toàn. “Claude Mythos Preview là, trên hầu như mọi phương diện chúng tôi có thể đo, mô hình được căn chỉnh tốt nhất mà chúng tôi từng phát hành, với khoảng cách đáng kể”, Anthropic lập luận. Nhưng họ cũng nói mô hình này “nhiều khả năng là mô hình có rủi ro liên quan đến căn chỉnh lớn nhất mà chúng tôi từng phát hành”.
Một mô hình mạnh hơn, hoạt động trong các môi trường có mức độ rủi ro cao hơn và ít giám sát hơn, tạo ra rủi ro đuôi mà ngay cả căn chỉnh trung bình tốt hơn cũng không thể bù trừ hoàn toàn.
Cách nhìn đó là trung thực, nhưng cũng cho thấy điều mà phần lớn diễn ngôn về an toàn AI có thể đã hiểu sai. Cuộc thảo luận quá ám ảnh với benchmark về tiến bộ AI thường xem “điểm căn chỉnh cao hơn” và “triển khai an toàn hơn” là đồng nghĩa. Card Mythos nói rõ rằng chúng không phải vậy. Với các mô hình mới này, hành vi trung bình có thể tốt hơn, nhưng hệ quả ở phần đuôi rủi ro cũng có xu hướng tồi tệ hơn.
Anthropic đã cam kết sẽ báo cáo lại những gì Project Glasswing tìm thấy. Báo cáo kỹ thuật đi kèm về các lỗ hổng mà Mythos phát hiện có sẵn tại red.anthropic.com. Mô hình Claude Opus tiếp theo sẽ bắt đầu thử nghiệm các cơ chế bảo vệ nhằm cuối cùng đưa năng lực kiểu Mythos đến với triển khai rộng hơn.
Cách những cơ chế bảo vệ đó sẽ được đánh giá ra sao, trong bối cảnh bộ máy đánh giá hiện tại đang căng ra dưới sức nặng của chính thứ nó phải đo lường, là câu hỏi mà card này đặt ra nhưng chưa trả lời trọn vẹn.
Tuyên bố miễn trừ: Bài viết này chỉ nhằm mục đích cung cấp thông tin dưới dạng blog cá nhân, không phải là khuyến nghị đầu tư. Nhà đầu tư cần tự nghiên cứu kỹ lưỡng trước khi đưa ra quyết định và chúng tôi không chịu trách nhiệm đối với bất kỳ quyết định đầu tư nào của bạn.
Theo Nghị quyết số 05/2025/NQ-CP ngày 09/09/2025 của Chính phủ về việc thí điểm triển khai thị trường tài sản số tại Việt Nam, CoinPhoton.com hiện chỉ cung cấp thông tin cho độc giả quốc tế và không phục vụ người dùng tại Việt Nam cho đến khi có hướng dẫn chính thức từ cơ quan chức năng.
Theo dõi chúng tôi ngay:
- Telegram: @coinphoton_vn
-
 X (Twitter):
@coinphoton_vi
X (Twitter):
@coinphoton_vi
-
 Discord:
@coinphoton_vn
Discord:
@coinphoton_vn

Trong thế giới công nghệ, nhắc đến Apple là nhắc đến sự đổi mới, sáng tạo và tầm ảnh hưởng toàn cầu. Đứng sau thành công rực rỡ của gã khổng lồ này từ năm 2011 đến nay là Tim Cook – vị CEO với phong cách lãnh đạo điềm… …

Apple, một trong những công ty công nghệ hàng đầu thế giới, từ lâu đã trở thành biểu tượng của sự đổi mới và sáng tạo. Được thành lập vào năm 1976 bởi Steve Jobs, Steve Wozniak và Ronald Wayne, Apple đã định hình lại cách con người tương tác… …

